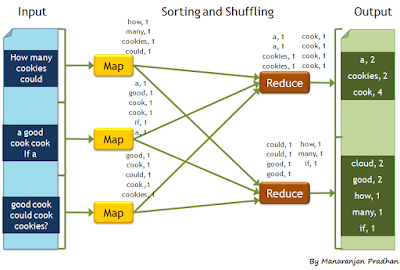
Setting up Heron Cluster with Apache Aurora Locally

In this post we will be looking at how we can setup Heron steam processing engine in Apache Aurora in our local machine. Oh Boy this is going to be a long post :D. I am doing this on Ubuntu 14.04 and these steps should be similar to any Linux machine. Heron supports deployment in Apache Aurora out of the box. Apache Aurora will act as the Scheduler for Heron after the setup is complete. In order to do this first you will have to setup Apache Zookeeper and allow Heron to communicate with it. Here Apache Zookeeper will act as the State Manager of the Heron deployment. if you just want to setup a local cluster without the hassle of installing aurora take a look at my previous blog post - Getting started with Heron stream processing engine in Ubuntu 14.04 Setting Up Apache Aurora Cluster locally First thing we need to do is to setup Apache Aurora locally. I will try to explain as much of the configurations as i can as we go on. First lets get a Apache Aurora cluster ...